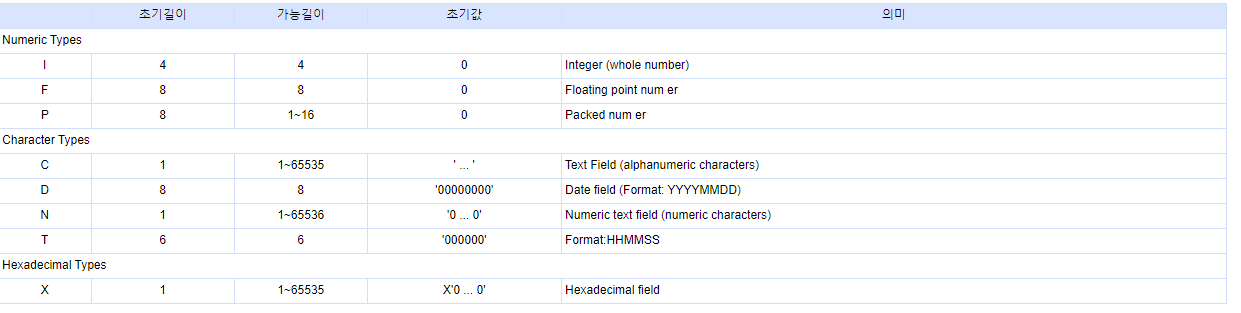
패스트캠퍼스의 올인원패키지 : 프론트엔드의 진유림 강사님의 GIT특강을 보고 정리 한 내용입니다.
서로 카톡이나 메일로 소스 공유하고 수정할 부분 찾아서 수정하고 합치고 다시 저장해서 서로 공유하고...
→ 너무 복잡하고 힘들다... 어디 고쳐야 할지도 헷갈리고...
→ 서로의 수정버젼이 다를 수 있고...
→ 마치 대학교 조별과제_완성.ppt, 조별과제_진짜완성.ppt... 같이 파일만 무수히 많아져서 공유하기도 힘들거고...
이러한 버전들을 관리하고 ( 완성본까지의 수정본까지 ) 원하는 버전을 가져오고 수정할수도 있고 합쳐서 관리에 매우 용이해진다
CLI와 GUI 두가지로 GIT 사용 가능
- 각각 장단점...이 있다
- 둘 다 할 줄 알아야 상황에 따라 대처하기 좋다.
절차
- 프로젝트 폴더 설정
- git init
- 코딩
- 원하는 파일 선택
- git add
- 선택한 파일들 병합
- git commit -m "~"
- 프로젝트 저장소 만들고
- 프로젝트 폴더에 저장소 주소 주고
- git remote add
- 내 컴퓨터에 프로젝트 폴더에 만든 덩어리 GitHub에 업로드
- git push
git init
- git init하면 기본으로 숨김 처리 된 폴더가 생기고 이 폴더를 로컬저장소라고 하는데 여기에서 버전 관리를 하게 됨, 직접적으로 건들일은 없고 명령어로 제어!
- 단 하나의 폴더에는 하나의 로컬저장소만 유지!
cmd로 원하는 디렉토리 가서 git init 명령어 입력
오류 발생한다면... 환경변수 다시 잡아주거나 git 설치경로 다시 한번 확인하기
README.md 파일 하나 만들고
git add [README.md](http://readme.md/)
git commit -m "README.md 추가"확인해보려면
git log다 추가하려면
git add .
git commit -m "다 추가"이러면 버전 생성됨.
- 의미있는 변동사항을 묶어서 커밋을 만들자
- 버튼 하나를 수정하는데 다수의 파일을 수정했다면 다수의 파일을 묶어서 커밋!
- 커밋 메시지는 꼭 작성하자.
여기까진 내 로컬 저장소에 버전관리 되고 있음
이걸 원격저장소 (Github)등에 올려서 온라인 및 타인과 버전 관리
git remot add origin https://github.com/아이디/이름.gitgit puch origin master기본 브랜치가 master이기에
나는 main!

git hub 로그인 해서 new repository하고
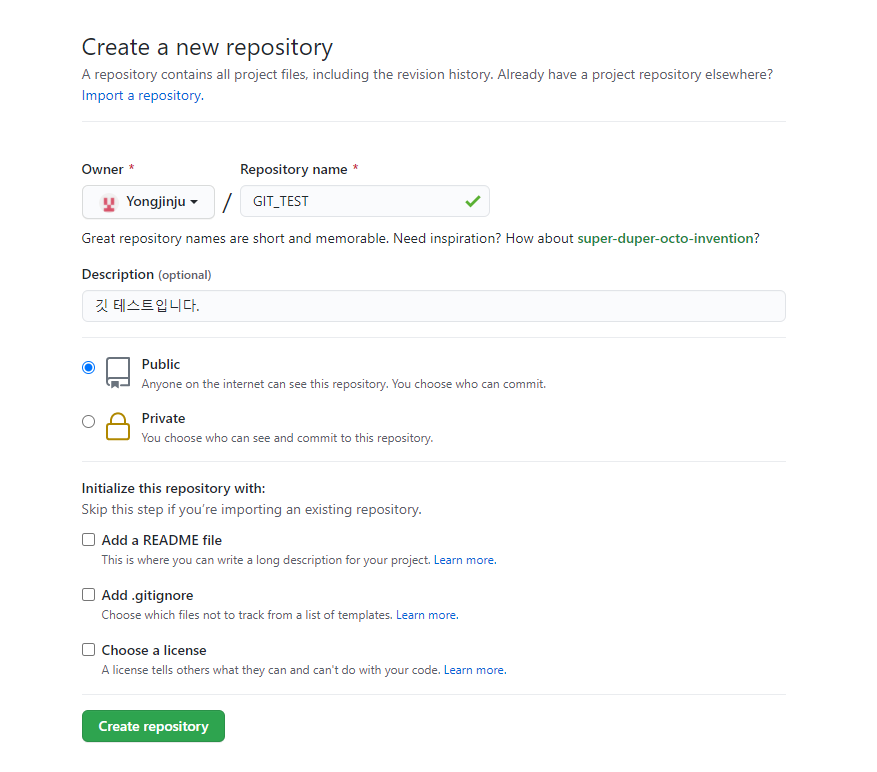
이렇게 만들어주기
만들고나서 cmd로 돌아가서
remote add와
push 해주자!